

We spoke in our past blog about what a sample is, and what are the best way of obtaining random sampling subgroups for testing. In this post, we will be discussing the importance of sample size.
Sample Size
We briefly said in our previous post that Bigger = Better and this is the case. A greater number of samples gives you a greater accuracy of the total population. But that doesn’t mean that we need a very large sample size.
We can use the average of a sample and the data that is away from the mean. Bear with me here as we get to delve into some statistical analysis geekiness.
Standard Deviation
We talk a lot about standard deviation in sample testing, and with good reason. Standard deviation is the average distance between the data point and the mean. Because all random data can be normalised, we can determine the probability that data points will fall in a certain point away from the mean of a data set or subset of values.
If we have a big enough data set we can quantify the uncertainty around the distribution of given values and the range of the values.
But first, let’s refresh ourselves with what a mean average is:
Mean
I always remember the mean because it was the meanest to calculate at school, and if you are an 8-year-old boy named George, calculating maths was not on the agenda. Pokemon cards were though… Some things never change.
So mean is an average worked out by adding up all the numbers in a sample and dividing them by the number of data points. An example:
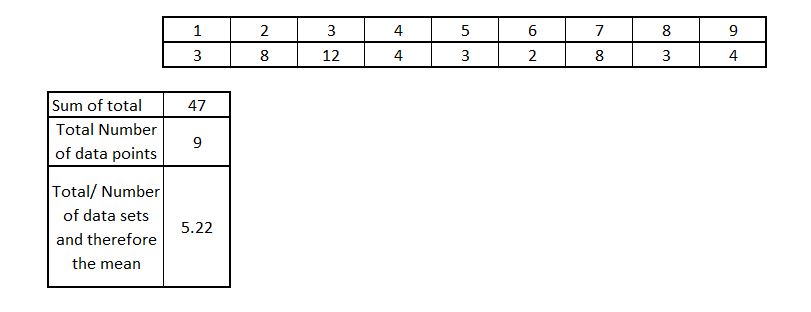
So as we can see the mean is 5.22. This independently does not mean much. But its a very important number when we need to calculate the standard deviation.
So as we said before the standard deviation is a distance from the mean. To be more precise its the squared distance from the mean. Don’t be too scared by that, or the below calculation below. It will all make sense soon:

Again, don’t get scared at the above, its merely showing us that we can work out very large populations of data from potentially much smaller populations of data.
Big Data from Small Data
We can see from the above, 68% of the data falls in the first standard deviations of mean (-1 and +1). 95% of the data within 2 standard deviations from the mean and 99.7% of all data should fall within 3 standard deviations of mean.
Each of these standard deviation points are 1 Sigma. Meaning that 99.7% of our data should span across Six Sigma points, or 6 standard deviations.
Can you see why its a good tool now?
Now the caveat to the above is that this only works when we have the well-centred bell-shaped curve.
We know that if selecting samples the majority of our data should fall within 3 standard deviations of our mean. If not, we know that we have problems in manufacturing defects.
And the best thing is to figure this out we can do some clever statistical analysis to determine if we have potential outliers, how many we have and if these are within the permitted accepted quality limit.
How this can help me sample data?
We will go into how this can help in a later blog post, but the fundamentals are, using standard deviation we can calculate an acceptance criteria based upon a mean of data. From this mean we can determine where 99.7% of data should lie. If we have data points that are outside of these points, we have a situation where we possibly need to reject or rework a batch of parts.
Don’t worry though
If the above seems a bit far fetched, don’t worry, luckily there is some pretty trick software that can work out sampling data for us. What I wanted to try and allow you to understand is that we can generate confidence levels from very small sample data. Hence the importance of sample size and what we can generate from it.
Conclusion
When we are sampling individual components for QC testing the first job is to ensure that there is a good sample selection that is free from bias.
That bias can come from a lot of individual factors. Even things such as ease of access to a product can influence the selection of samples. So it’s important to ensure you select samples in an unbiased, isolated way.
Do you want stock checking? Get in touch with us to go through your requirements to ensure you have all your QC bases covered. Or hit us up on LinkedIn for regular updates.