

Quality control is the ability to capture issues before they leave the factory and end up in your customers hands. Sample testing is the best technique to indicate if a shipment/ batch is acceptable or not. But how to choose a sample for statistical analysis let’s discuss how to choose components and understand if we can use, or need to reject components.
There are numerous different types of statistical analysis we use to determine if a batch is to be accepted. But first, let’s start right at the bottom.
What is a sample?
A sample is a subset of the total population. This smaller portion of a larger population can act as a representation of the total population.
But, it’s very important that if we are to use this smaller portion of a larger population we must keep a true representation; or it would be a waste of time and effort and the final result will be biased (we will go into bias later).
Bigger = Better
Have you ever heard the phrase bigger is better? Well, sample sizes are no exception to this statement. The bigger the sample the more representative of the population it will be.
But hang on a minute, if it was so big then surely there would be no reason to sample at all. Also, large sample sizes can just be in-appropriate, expensive and time-consuming.
What to measure?
So we have determined that we cannot measure everything, but equally a sample needs to tell us the following:
- What will happen next?
- What is happening now?
- Where do we need to improve?
- What is normal?
And the sample needs to be free from bias.
This leads us to a big statement. Samples need to be…..
Random!
In a random sample, each individual has the same probability of being chosen at any stage. Each subset of the sample has the same probability of subset to be selected.
It’s surprisingly difficult to select a random sample of anything.
Why?
We need samples that are unbiased (or our results will be incorrect) and have independent data sources. The selection of an individual item must not influence the selection of other units.
We have a few methods to collect random samples.
Systematic Sample
A systematic sample uses a K number. The K number is a selection then followed by a number of items (the K number) and then an item selected.
An example being this:

The above selection has a K number of 3 (K=3). The first number selected being 3 (the actual first number does not actually always have to correlate to the K number) but the following numbers do. The first number selected was 3, then every 3rd number after this was selected. Hence having a K number of 3.
This systematic sample selection, although looking simple to implement, does have the ability to introduce some bias into the system.
An example would be taking a sample selection using the above technique during a very warm day, when say for example a machine was working differently due to external environmental factors. Or a survey was being conducted on people exiting a shop and samples were only taken at dinner time.
You would be potentially adding bias into your sample population. So using Systematic sampling should be used with caution.
Opportunity sample
This instead of using a K number, we move onto an n number. In the below example we have an n=7:

We see the first number that is selected is 7 (again 7 just happens to fall on 7, it bears no correlation to the n number) and the following 6 numbers. This gives us an n number of 7. Again we need to be careful of bias here.
If we have a sample that is grouped like this we may have some variables that are repeated entering into the mix.
In my opinion, the following is a better solution than these two selections:
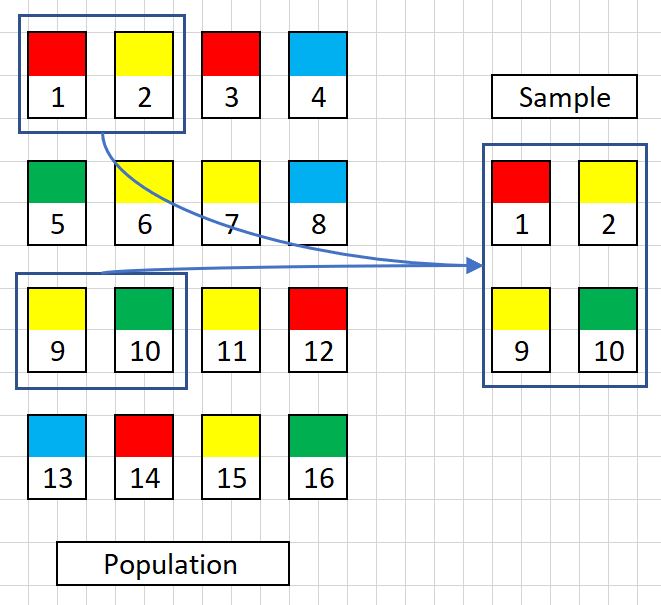
Stratified Sample
This is where a sample in which populations of individual samples are broken up into homogenous groups. This has the added benefit of the sample being a more unbiased range of data from the population.
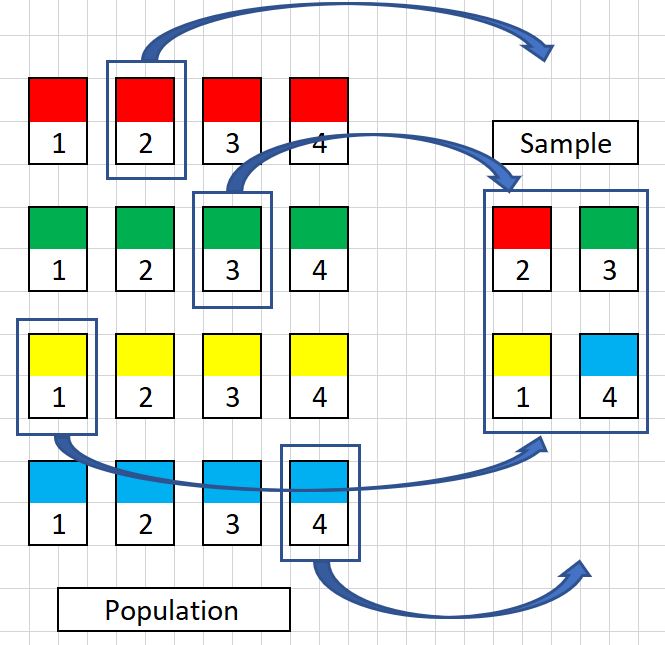
Cluster Sample
The cluster sample is very similar to the stratified sample selection technique but breaking things into groups. The groups are assigned randomly and have no (or as little bias) as possible going into the selection of the groups. Again the groups are then selected at random to go into the sample.
Conclusion
When we are sampling individual components for QC testing the first job is to ensure that there is a good sample selection that is free from bias.
That bias can come from a lot of individual factors. Even things such as ease of access to a product can influence the selection of samples. So it’s important to ensure you select samples in an unbiased, isolated way.
Do you want stock checking? Get in touch with us to go through your requirements to ensure you have all your QC bases covered.